AMD Instinct MI250, PyTorch 2.0 ve ROCm 5.4 ile Arttırılmış Yapay Zeka Performansını Görüyor, LLM’lerde NVIDIA GPU’lara Yaklaşıyor
– Advertisement –
MI250 gibi AMD Instinct GPU’ları, AI performansında büyük bir artış elde ederek onları NVIDIA’nın yongalarına yaklaştırdı.



AMD, PyTorch 2.0 ve ROCm 5.4 Sürümleriyle NVIDIA’nın LLM AI Eğitim Hızlarına Yaklaşıyor, Instinct MI250, A100 ile Neredeyse Eşit
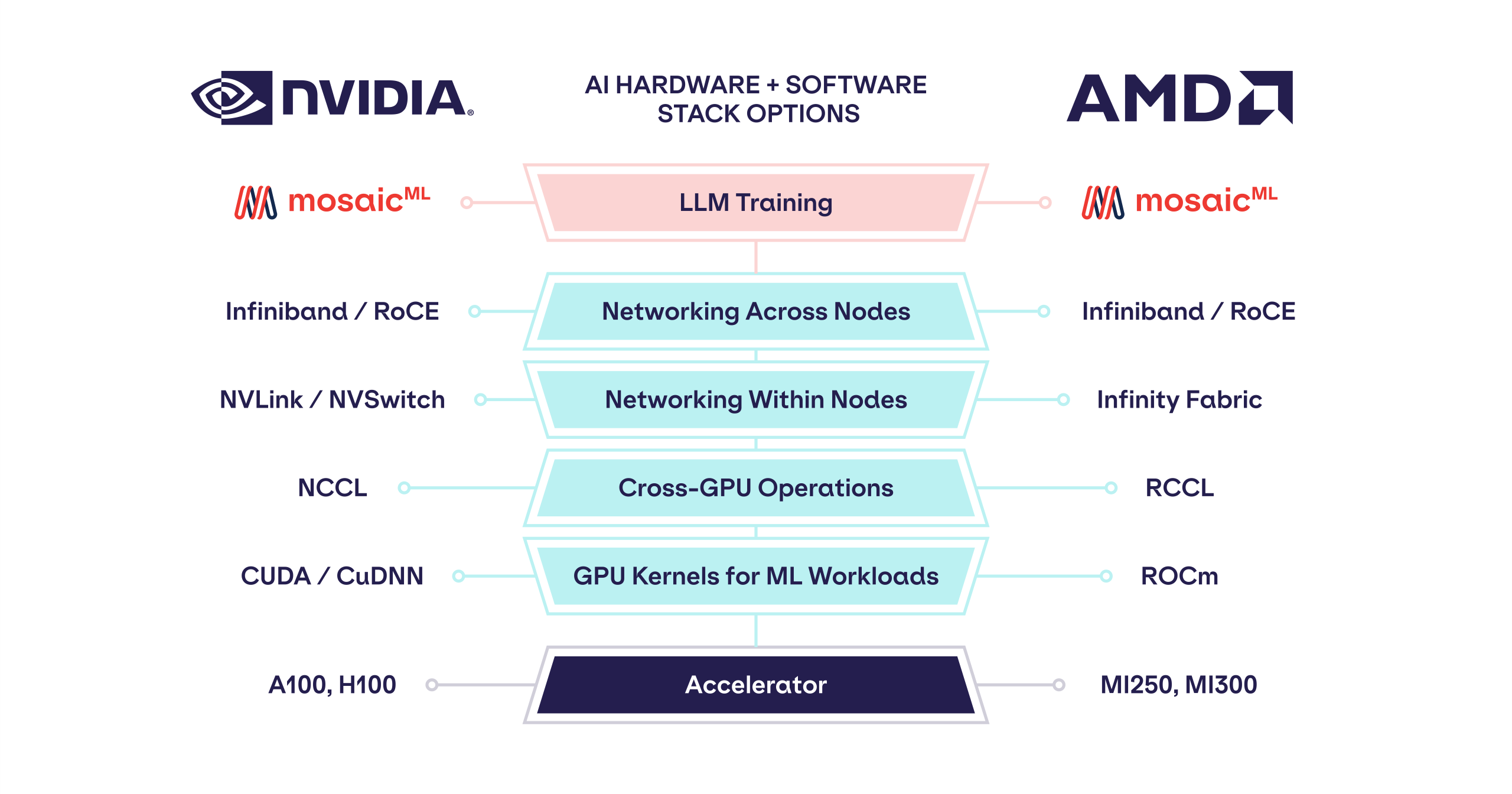
PyTorch 2.0 ve ROCM 5.4’ün herhangi bir kod değişikliği olmadan Instinct serisi gibi AMD Veri Merkezi GPU’larının performansını artırmaya nasıl yardımcı olduğunu gösterdi.
Yazılım satıcısı, NVIDIA ve AMD’nin 16 bit hassasiyeti (FP16 / BF16) destekleyen çok çeşitli çözümlerinde makine öğrenimi ve LLM eğitimi için gelişmiş destek sunar. Son sürümler, MosaicML’nin, LLM Foundry Stack kullanımıyla AMD Instinct hızlandırıcılarından daha iyi performans almadığı sürece, izin verdi.
Sonuçlardan öne çıkanlar şöyle oldu:
- LLM eğitimi istikrarlıydı. Son derece belirleyici LLM Foundry eğitim yığınımızla, bir MPT-1B LLM modelini AMD MI250’ye karşı NVIDIA A100 üzerinde eğitmek, aynı kontrol noktasından başlarken neredeyse aynı kayıp eğrileri üretti. Hatta tek bir eğitimde AMD ve NVIDIA arasında geçiş yapabildik!
- Performans rekabetçiydi mevcut A100 sistemlerimizle. MPT modellerinin eğitim verimini 1B’den 13B parametrelerine kadar profilledik ve MI250’nin GPU başına veriminin A100-40GB’nin %80’i ve A100-80GB’nin %73’ü içinde olduğunu bulduk. AMD yazılımı geliştikçe bu açığın kapanmasını bekliyoruz.
- Hepsi işe yarıyor. Kod değişikliğine gerek yoktu.
AMD’nin Instinct MI250 GPU’su, FP16 FLOP’lar (seyrekliksiz), bellek kapasitesi ve bellek bant genişliği açısından NVIDIA A100 GPU’lara göre hafif bir avantaj sunarken, MI250’nin yalnızca 4 hızlandırıcıya kadar ölçeklenebildiği, oysa NVIDIA A100 GPU’ların ölçeklenebildiği unutulmamalıdır. tek bir sistemde 8 adede kadar GPU.

Daha derinlemesine bakıldığında, hem AMD hem de NVIDIA donanımı, LLM dökümhanesi ile yapay zeka eğitim iş yüklerini kolaylıkla başlatabildi. Performans iki eğitim iş yükünde değerlendirildi, ilki genel aktarım hızıydı (Token/Sn/GPU) ve diğeri genel performanstı (TFLOP/Sn/GPU).

Yapay Zeka Eğitim Verimi, 1 Milyar ila 13 Milyar parametre aralığındaki modellerde gerçekleştirildi. Testler, AMD Instinct MI250’nin NVIDIA’nın A100 40 GB performansının %80’ini ve 80 GB varyantının performansının %73’ünü sağladığını gösterdi.
NVIDIA, tüm kıyaslamalarda liderlik konumunu korudu, ancak testlerde iki kat daha fazla GPU çalıştırdıkları da belirtilmelidir. Ayrıca, gelecekte AMD Instinct hızlandırıcıları için eğitim tarafında daha fazla iyileştirme beklendiğinden bahsediliyor.
AMD şimdiden işini yapıyor. Şirket, çipin tek bir çözümde 40 Milyar parametreli bir LLM modelini nasıl işlediğini gösterdi. MI300 ayrıca 8 adede kadar GPU ve APU konfigürasyonunda ölçeklenebilir.
Çip, NVIDIA’nın H100’üne karşı rekabet edecek ve ne olursa olsun yeşil takım önümüzdeki yıl piyasaya sürülmek için çalışıyor. MI300, 192 GB HBM3 ve NVIDIA’nın çözümünden çok daha yüksek bir bant genişliğinde herhangi bir GPU’da en yüksek bellek kapasitesini sunacak.
AMD cephesindeki bu yazılımsal gelişmelerin rekabeti yakalamaya yetip yetmeyeceğini görmek ilginç olacak. NVIDIA’nın AI alanında elde ettiği %90’dan fazla pazar payı.